Neste post, vamos apresentar mais um método para previsão de vitória. Desta vez, utilizaremos como variável principal o valor de mercado dos times, que corresponde à soma dos valores de mercado individuais de todos os jogadores da equipe. Vamos explorar como essa métrica pode influenciar o desempenho dos clubes e sua chance de vencer uma partida.
Contextualização
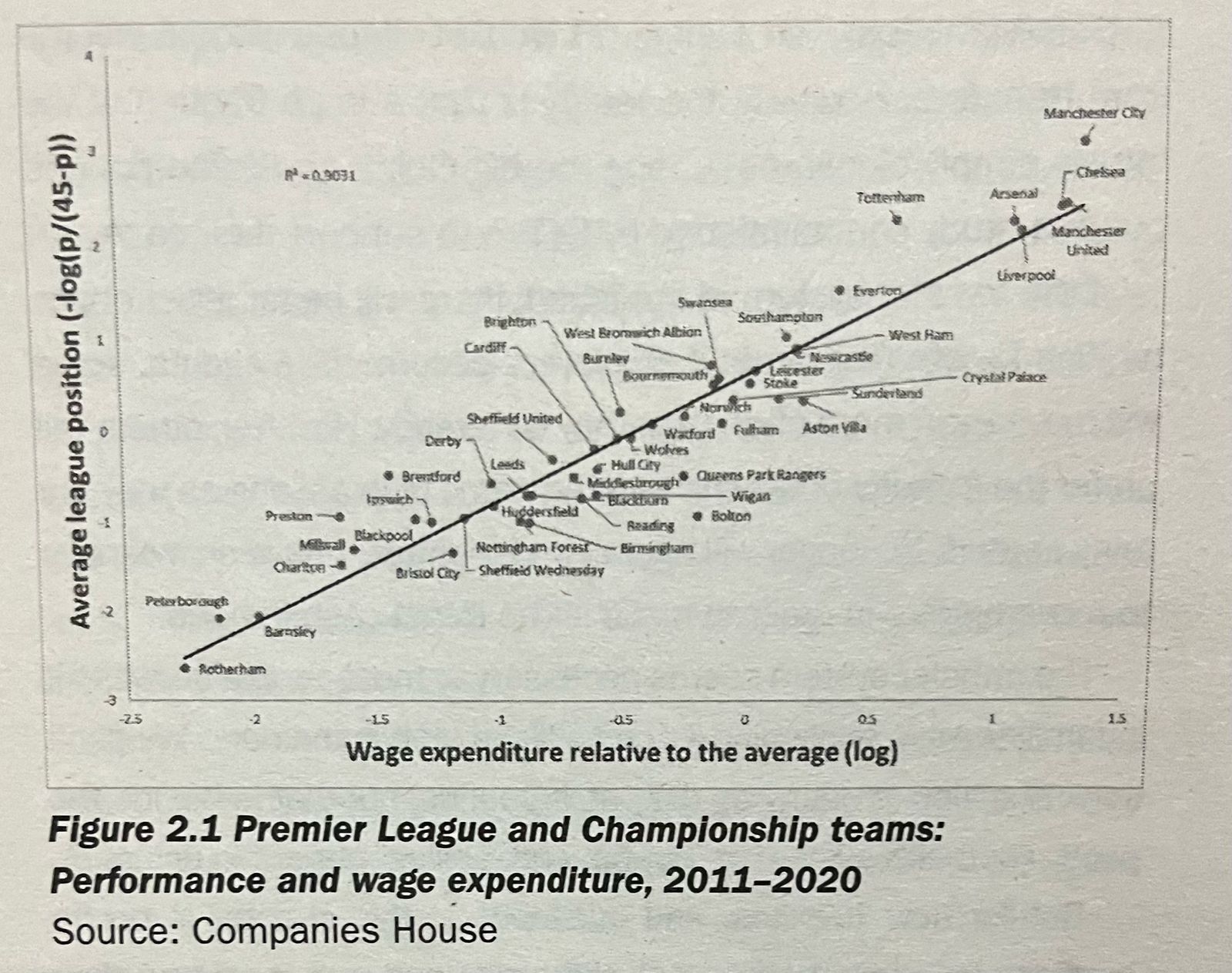
O dinheiro tem um grande papel no futebol moderno. Com o mercado de transferências cada vez mais inflacionado, mostra-se necessário gastar cada vez mais dinheiro nas janelas de transferências para manter a competitividade nas maiores ligas. A exponente profissionalização do esporte também possui grande influência no encarecimento do custo de manter um time, visto que atualmente são necessários mais gastos em estrutura e um ambiente de qualidade para se manter na frente dos demais. Inclusive, estudos na Premier League e Championship (2011-2020) mostraram que existe uma correlação entre a folha salarial de um time e a posição que esse time alcança na tabela (Soccernomics, Simon Kuper e Stefan Szymansk). O dinheiro move o futebol. Por isso, vamos utilizar o valor de mercado dos clubes do Brasileirão para tentar prever o resultado final das partidas.
Método
Dados
Nós iremos usar os dados da temporada 2023. O dataset tem duas partes principais:
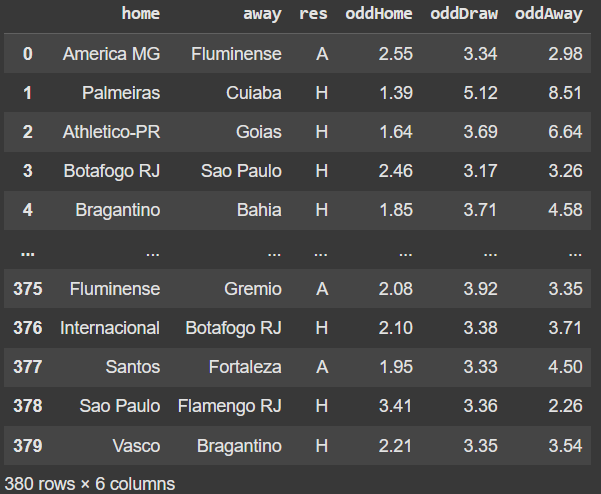
Os dados das partidas: informações como time da casa, time visitante, resultado, data da partida e odds de vitória (casa, empate, visitante), extraídas do site <a href = (https://football-data.co.uk/)">Footbal-data</a> e da casa de apostas Pinnacle.
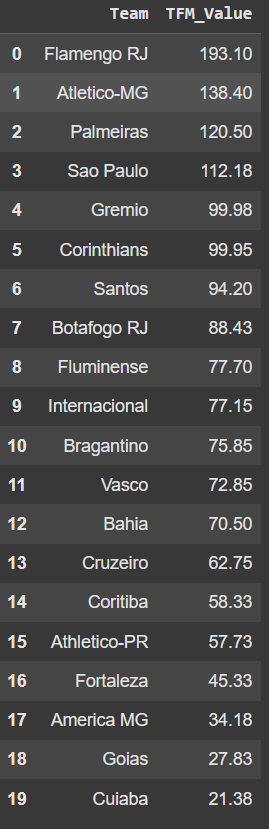
O valor de mercado dos times do Brasileirão 2023, retirados do site Transfermarkt.
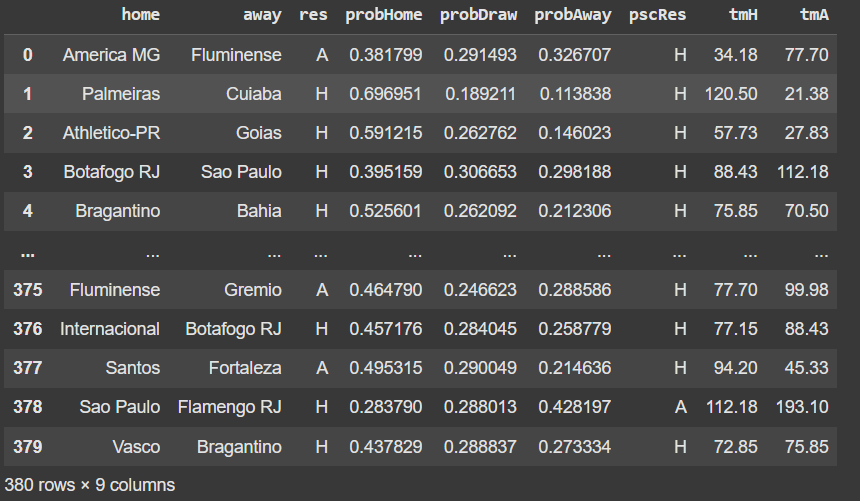
Vamos agora dar uma olhada no nosso dataset das partidas. Ele possui cerca de 19 campos, mas só os seguintes nos interessam:
Legenda: home: Time mandante; away: Time visitante; res: Resultado da partida; oddHome: Chance da vitória do time mandante; oddDraw: Chance do empate; oddAway: Chance da vitória do time visitante.
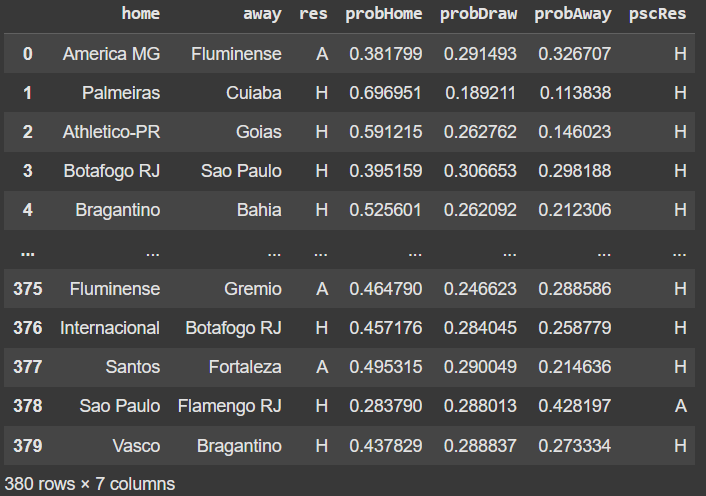
Iremos transformar odds em probabilidades. Para isso, não utilizamos apenas a fórmula (1/odds), pois a soma das probabilidades seria maior que 1. Esse excesso representa a margem de lucro das casas de apostas, então normalizamos as probabilidades para corrigi-la.
Vamos observar os dados de valor de mercado agora:</br>
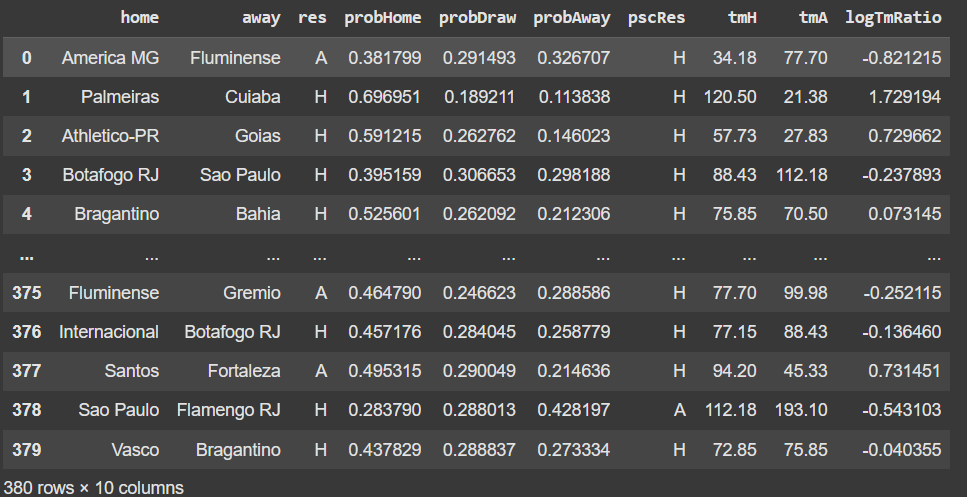
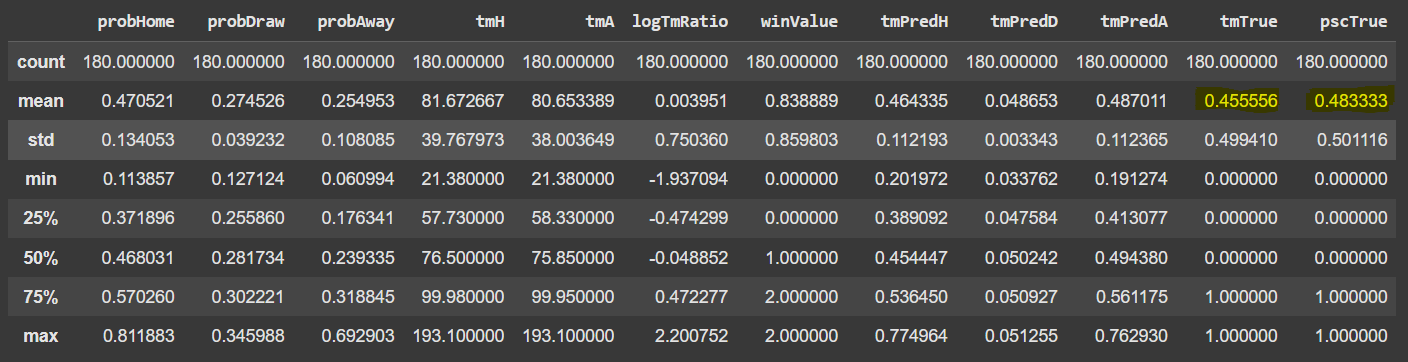
A coluna TFM_Value contém o valor de mercado em milhões de euros. Por exemplo, o valor de mercado do Palmeiras é de 138,4 milhões de euros. Esses dados representam os valores de mercado dos clubes no dia 20 de Julho de 2024. Unimos os dois datasets, adicionando as colunas de valor de mercado do time da casa (tmH) e do visitante (tmA).
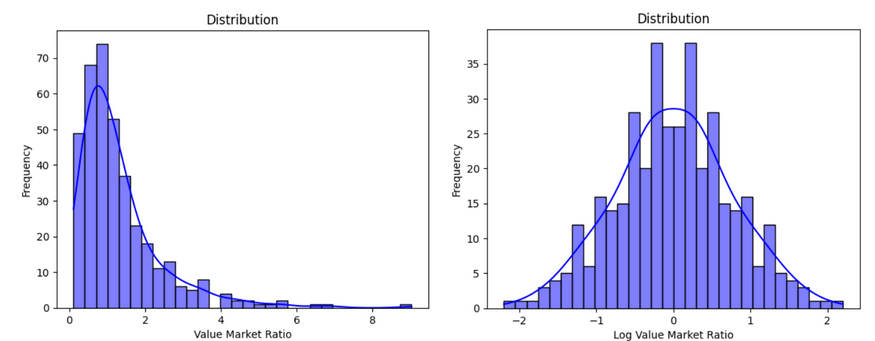
A variável que vamos utilizar para realizar a previsão de resultados é a razão entre o tmH (valor de mercado do time da casa) e tmA (valor de mercado do time da visitante). Mais especificamente o logaritmo dessa razão. O motivo de utilizarmos o log é pelo fato de que a distribuição da razão entre tmH e tmA estar inclinada para a direita. A aplicação da função log leva a uma distribuição simétrica, o que melhora a performance. A imagem abaixo ajudam a visualizar isso.
Então o logTmRatio será a variável que iremos utilizar para a previsão de resultados. Em outras palavras, a nossa variável independente.
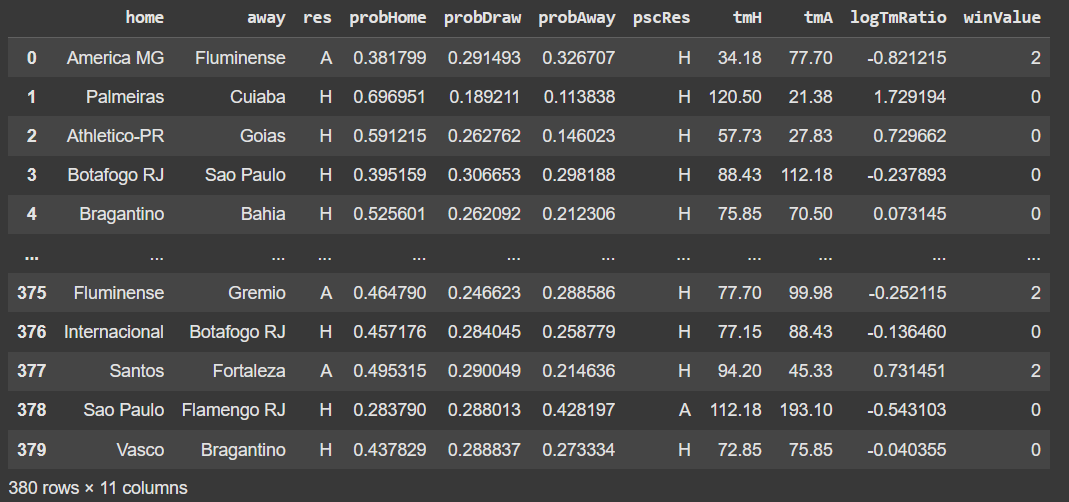
Codificamos a coluna res com:
0: vitória do time da casa
1: empate
2: vitória do time visitante
Essa nova coluna será chamada de winValue.
Modelo
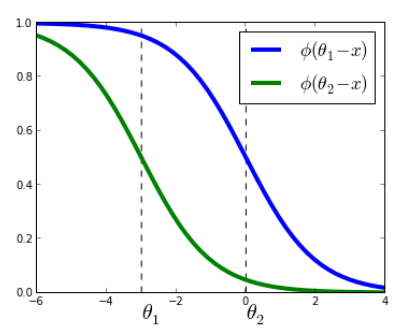
Nós iremos usar um modelo de Regressão Logística Ordinal que consiste em uma técnica utilizada para modelar a relação entre uma variável de resposta ordinal, ou seja categorias que possuem ordem, e uma ou mais variáveis preditoras. No nosso caso, a variável de resposta ordinal é o winValue e a variável preditora será o logTmRatio. O modelo consiste em descobrirmos o \( \alpha_1 \) que é o ponto que divide a vitória do mandante e empate ou vitória do visitante, ou seja, se um ponto cair antes de \( \alpha_1 \), o modelo preverá a vitória do mandante e se cair após \( \alpha_1 \), preverá o empate ou vitória do visitante. Já o \( \alpha_2 \) é o ponto que divide o empate e a vitória do visitante. O \( \beta \) indica como a variável preditiva, no nosso caso a razão do valor de mercado, influencia no resultado. Para uma melhor visualização dessa explicação, basta observar o gráfico abaixo, no qual o \( \alpha_1 \) é representado por \( \theta_1 \):
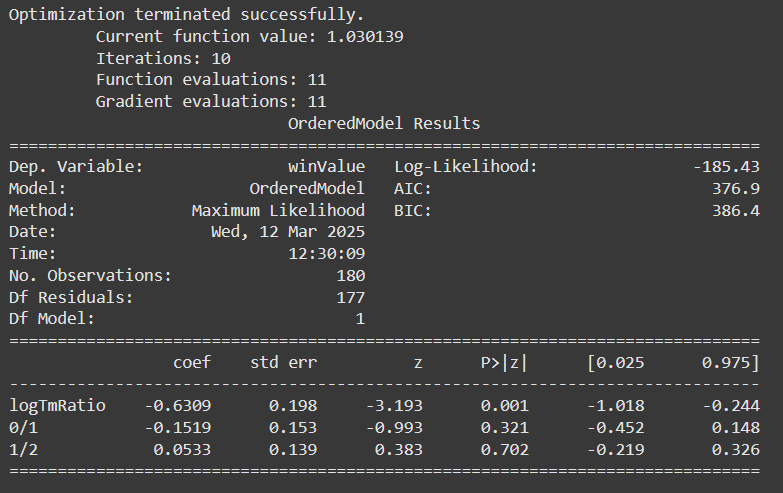
Usamos um modelo de Regressão Logística Ordinal, que relaciona uma variável resposta ordinal (winValue) a uma preditora contínua (logTmRatio). O modelo encontra dois pontos de corte:
\( \alpha_1 \): separa vitória do mandante de empate ou vitória do visitante
\( \alpha_2 \): separa empate de vitória do visitante
\( \beta \): nos diz como essa razão influencia o resultado do coeficiente de logTmRatio
Agora que entendemos sobre o modelo, vamos preparar o seu treinamento. O dataset de treino consiste nos primeiros 200 jogos da temporada e os 180 jogos restantes serão usados como dataset de teste.
Vamos adicionar colunas que compare os resultados de previsão da Pinnacle e o que encontramos.
Avaliação
Lembrando que utilizamos os primeiros 200 jogos para treinar o nosso modelo, por isso vamos comparar os resultados de previsão do nosso conjunto de teste.
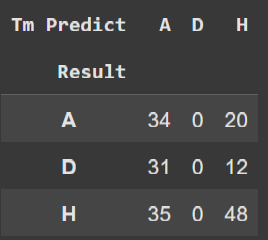
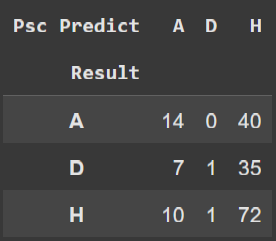
O valor que mais nos interessa está destacado que é a média de acertos de resultados da casa de apostas e do nosso modelo. Repare que são valores próximos e até mesmo a casa de apostas teve menos de 50% de acerto. Uma coisa importante para se considerar ao analisar esses dados é o tamanho do conjunto de treino que só teve 200 partidas e obtivemos um resultado de 0.03 de diferença para a casa de aposta. Vamos fazer duas tabelas cruzadas para entendermos melhor em quais tipos de jogos nosso modelo mais erra e acerta.
Note que na coluna de empates o nosso modelo não previu empates, isso é causado pelo fato de que a razão entre o valor de mercado de dois times têm uma probabilidade muito baixa de se relacionar com empate, já que se imagina que os valores de mercados do times teriam que ser próximos entre si.
Os números estão bem dispersos, mas percebesse que o nosso modelo acerta mais do que o Pinnacle no quesito vitória do visitante, enquanto a Pinnacle tem a maioria dos seus acertos nas vitórias dos times da casa.
Conclusão
No próximo post, abordaremos a previsão de resultados com base na distribuição de Poisson, uma famosa distribuição usada para prever eventos raros. Fique atento às nossas redes sociais para não perder nenhuma novidade do blog!